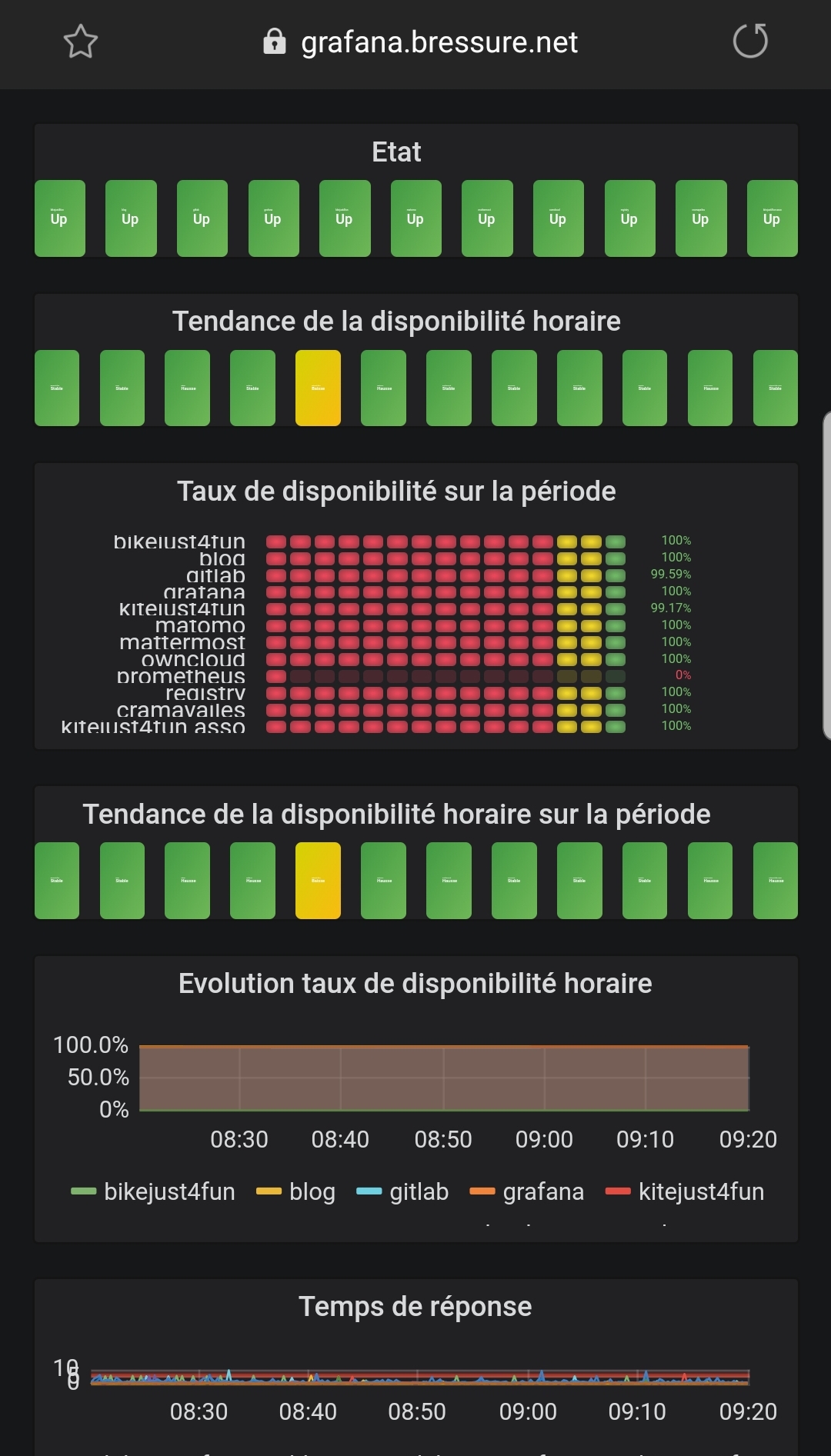
Dans l’article précédent je mettais en place les sondes blackbox pour Prometheus afin de tester la disponibilité de mes applications. Ces sondes placées à des endroits stratégiques doivent permettent également de diagnostiquer l’emplacement du problème eventuel dans l’architecture. Définition de la disponibilité J’utilisais jusque-là d’une part sur mon smartphone l’application Nock Nock qui verifie que […]
La mise en place du node exporter pour apache me permet de surveiller mon reverse proxy. Je peux ainsi m’assurer que mon infra est bien accesssible. Cela ne m’assure pas que les services qui sont derrière le reverse proxy sont bien accessibles. Définition de l’accessibilité Que le reverse proxy fonctionne est une condition nécessaire, que […]
Dans le remplacement de Munin par Prometheus, les indicateurs systèmes (OS et docker) sont en place. Avant de supprimer munin de mes machines, il reste encore quelques éléments à reprendre commme les métriques de: Apache (frontal et reverse proxy) KVM Mail Fail2ban Queue d’impression (utile ?) Commençons par la surveillance de apache Apache exporter Sur […]
Remplacer munin par Prometheus se serait complet sans la partie envoi des alertes. Dans mon cas un simple mail suffira. Alertmanager Comme tout est dockerisé chez moi, je vais donc ajouter dans mon application de monitoring le service alertmanager. Le rôle de l’alertmanager est de recevoir les demandes de notification quand une métrique a une […]
J’ai eu surprise de voir que ma surveillance ne fonctionnait plus avant hier. Pourtant d’après la capture prise vendredi soir tout semblait fonctionner. Il y a 2 jours la connexion entre mon conteneur Prometheus et les conteneurs prom-node et cAdvisor situés sur des VM étaient devenu impossible. Toute la configuration reseau est du standard à […]
Après avoir réglé mes soucis de mise à jour de Owncloud, je me suis remis à mes aventures avec Prometheus et Grafana. Config de Prometheus embarquée Comme mon infrastructure ne change pas entre mes environnements, j’ai tout d’abord pensé mettre le fichier de configuragion /etc/prometheus/prometheus.yml dans l’image docker de prometheus. Le code source final de […]
Jusque là j’utilisais le bien connu munin pour suivre l’état de mes serveurs et services. Cet outil assez ancien se positionne bien en tant que surveillance système et pour des alertes en cas de détection de valeurs anormales. Étant depuis plusieurs mois passé à une infra dockerisé, mon outils de monitoring était encore en natif. […]