J’utilise depuis près d’une an et demi le gitlab-runner comme outil de déploiement. En effet au sein du CI/CD il me suffit d’utiliser un runner positionné sur la bonne machine cible et je dispose alors d’un clone des sources. Puis il me suffit d’indiquer dans le gitlab-ci de lancer l’application par une incantation de type:
docker-compose up -d
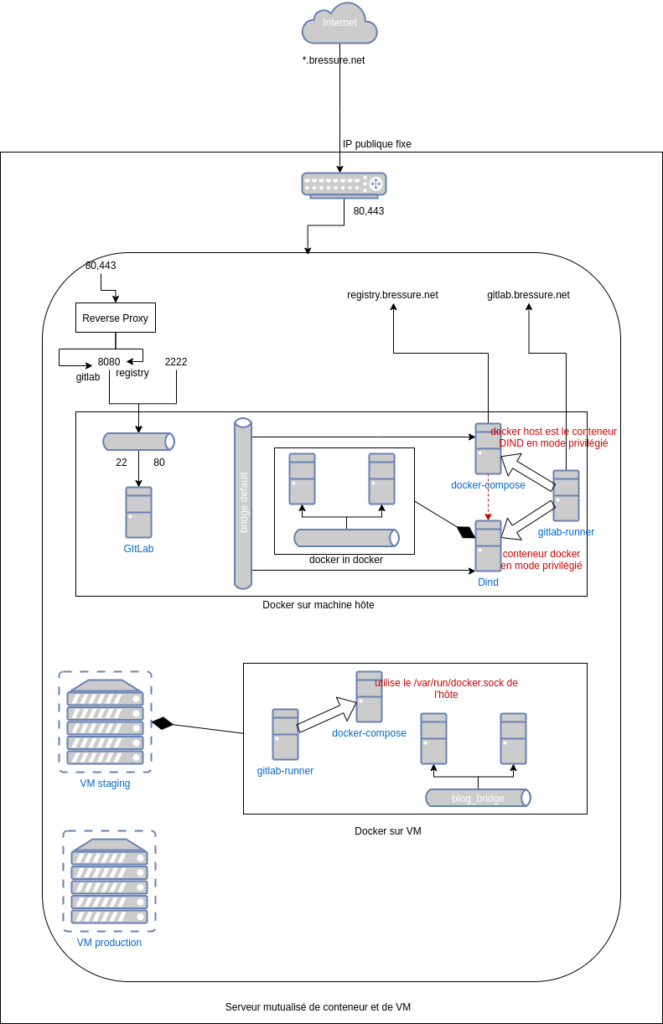
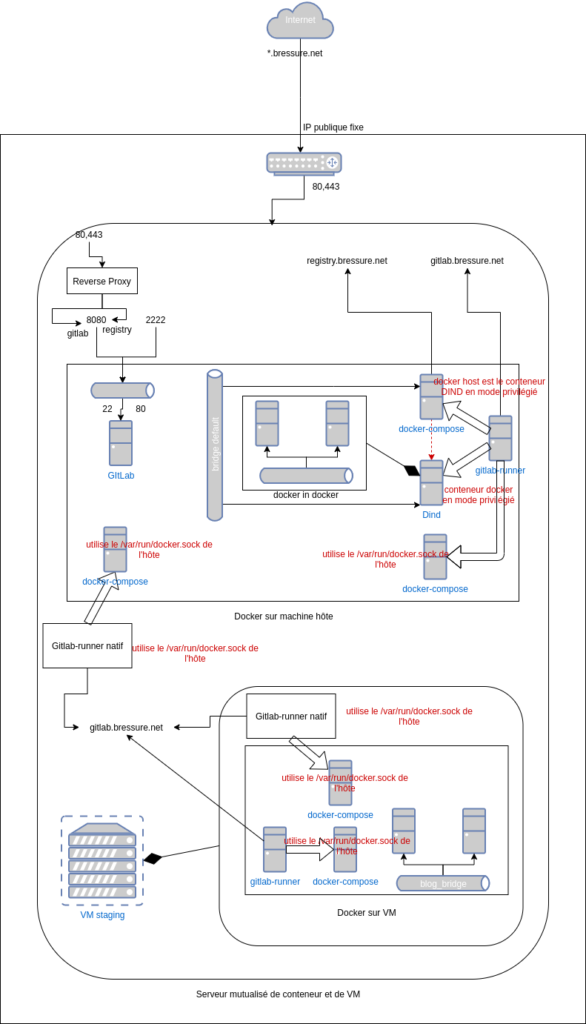
Avantages du runner
Ce moyen permet d’éviter de gérer le rapatriement des binaires à déployer. Dans le cas d’une application docker-compose le binaire c’est le fichier compose. Donc le git clone réalisé par le runner répond à ce besoin de rapatriement. En corollaire on voit qu’il n’est pas nécessaire de gérer un dépôt de binaires ou d’artefacts tel que Nexus puisque c’est le dépôt de source qui fait office de dépôt de binaire.
- pas de dépôts de binaires
- pas de rapatriement de binaires
- pas besoin de gérer le rapatriement des sources
Limites de cette méthode artisanale
C’est une méthode qui fonctionne bien dans le cas d’application docker-compose. Néanmoins on voit clairement que dans le cas général où une application ne s’exécute pas à partir de ses source que cela ne suffit pas.
Déployer des sources
Il faudrait reconstruire l’application ce qui est normalement possible car on fait tout pour que la construction soit répétable Il y a d’ailleurs des distributions Linux qui compilent les applications pour les installer. Je pense notamment à Gentoo. Cela pose alors le problème de puissance de traitement: compiler c’est coûteux ! très coûteux.
Un runner par cible
Comme le runner s’exécute sur la machine cible, même dans le cas favorable où l’application s’exécute à partir des sources, il faut installer le runner sur cette machine cible. C’est un tâche d’administration fastidieuse.
Lors de la mise en place de mon instance Mediagoblin je voulais avoir un environnement où déployer la branche de développement. Je voulais que cet environnement soit physiquement et logiquement disinct bien sur de la production et de la pré-production.
Pour cela il faut installer un runner sur l’environnement d’exécution de la branche de développement et inscrire le runner à Gitlab. Mais ce n’est pas tout.
Imbrication avec le gitlab-ci
Pour que le runner soit utilisé afin de déployer sur l’environnement ciblé, il faut qu’une étape dédiée dans le pipeline de construction soit configurée. Cette étape doit sélectionner le runner et donc l’étape est dédié à un environnement. On voit que l’ajout d’environnement à la volée n’est pas sans intervention manuelle:
- ajouter un runner sur la machine cible
- relier le runner à GitLab
- modifier le gilab-ci de l’application pour inclure une étape dédié à l’environnement
Environnement à la volée
Or je vais avoir besoin d’environnement en masse si je veux pousser le concept de branche vivante à toutes les branches d’un projet. Je veux pouvoir créer un environnement dès que je veux exécuter une branche. Ainsi une branche dédiée à une fonctionnalité ( branche dite feature), n’est plus cantonnée au stade du développement. Ce que jeux dire c’est qu’on pourra voir l’exécution de l’application correspondant à cette branche sur un environnement accessible à tous, sans passer par l’application qui tourne sur le poste du développeur.

Le fameux « ça marche chez moi » pourra réellement être vérifiable et même « démonstrable ». Une branche de feature qui n’est pas encore remontée sur la branche de développement (branche qui possède son environnement vivant au même titre que la prod ou la staging) pourra faire l’objet d’une démonstration. Toute le réglage d’infra pour rendre cela possible doit être automatique !
Solution temporaire
Comme actuellement je développe beaucoup j’ai besoin au moins d’un environnement de déploiement pour la branche de développement. Afin de limiter le travail d’installation de runner et de configuration de mon reverse proxy TLS, je vais me servir de l’environnement staging qui existe sur mon infra pour y déployer les applications en cours de développement. Moyennant une adaptation du gitlab-ci pour modifier le fichier compose staging j’arrive à avoir le fameux environnement live !

La modification du fichier compose est effectuée par une étape du CI/CD dédiée au déploiement des branches. Ici le squelette utilisé par le prochet archetype de type application pour générer le gitlab-ci :
deploy_review:
stage: staging
tags:
- infra
- docker
- regular
script:
- echo "Deploy a review app"
# ajouter un déploiement avec docker-compose
- echo "on fabrique un docker-compose spécifique"
- sed -i "s/%%NOM_PROJET%%.bressure.net/$CI_ENVIRONMENT_SLUG.bressure.net/g" docker-compose.staging.yml
- sed -i "s/staging_%%NOM_PROJET%%/$CI_ENVIRONMENT_SLUG/g" docker-compose.staging.yml
- docker-compose pull
- docker-compose -p $CI_ENVIRONMENT_SLUG -f docker-compose.yml -f docker-compose.staging.yml up -d
environment:
name: review/$CI_COMMIT_REF_NAME
url: https://$CI_ENVIRONMENT_SLUG.bressure.net:444
on_stop : stop_review
only:
- branches
except:
- master
Au même titre que staging cet environnement n’est pas public et n’est accessible que depuis mon réseau interne. C’est une bonne chose. Toutes les branches bénéficient d’un déploiement sur un environnement live. C’est une bonne chose aussi. En revanche on surcharge l’infra et la positionnement physique de l’environnement sur l’infra se fait via un concept gitlab dans le CI/CD parle choix du runner en fonction des tag infra, docker et regular. La solution reste donc imbriquée et dépendant de GitLab. Décider de déployer par exemple sur une autre machine signifie modifier le gitlab-ci. Or la configuration du déploiement ne devait pas être du ressort du gitlab-ci. C’est une solution temporaire en attendant la suite.
Vers un déploiement industriel
Quand je me contentais de 2 environnements : prod et staging, je ne voyais pas l’utilité de mettre en place une méthode plus industrielle. Mais lorsque j’ai commencé avec Mediagoblin à capitaliser sur la création de projet dans GitLab à travers les archetype de génération de projet, j’ai mis en lumière les limitations évoquées précédemment.
Les caractéristique de l’infrastructure et de l’outillage que je veux mettre place pour dépasser ces limitations sont les suivantes:
- archetype de génération pouvant permettre la prise en charge des projets non docker ou non docker-compose. Cela va passer par une ré-ingénierie de la conception des archetypes. Il faut factoriser les concepts non liés à docker ou docker-compose et les rendre surchargeables par le projet.
- Tout déploiement doit se faire à partir de livrables versionnés et non plus les sources: on pourra utiliser le dépôt de livrable de GitLab puisqu’on utilise déjà son registry pour le dépot des images pour les projet docker. Je pense à étendre cela au projet docker-compose par téléchargement du livrable au lieu de se baser sur les sources clonés par le runner
- déploiement par un « serveur » de déploiement unique pour tous les environnements : le terme serveur peut être vue comme une boîte, je pense bien-sur à développer un outil conteneurisé qui s’occupe du déploiement.
Afin d’aller vers la cible suivante où le runner ne définit plus l’environnement d’exécution et les runners sont virtuellement interchangeables quel que soit leur localisation !
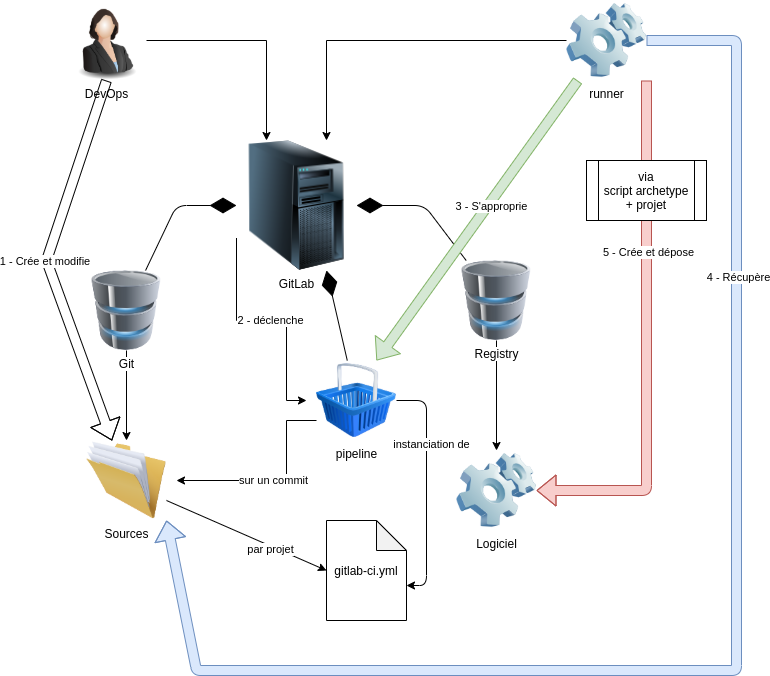
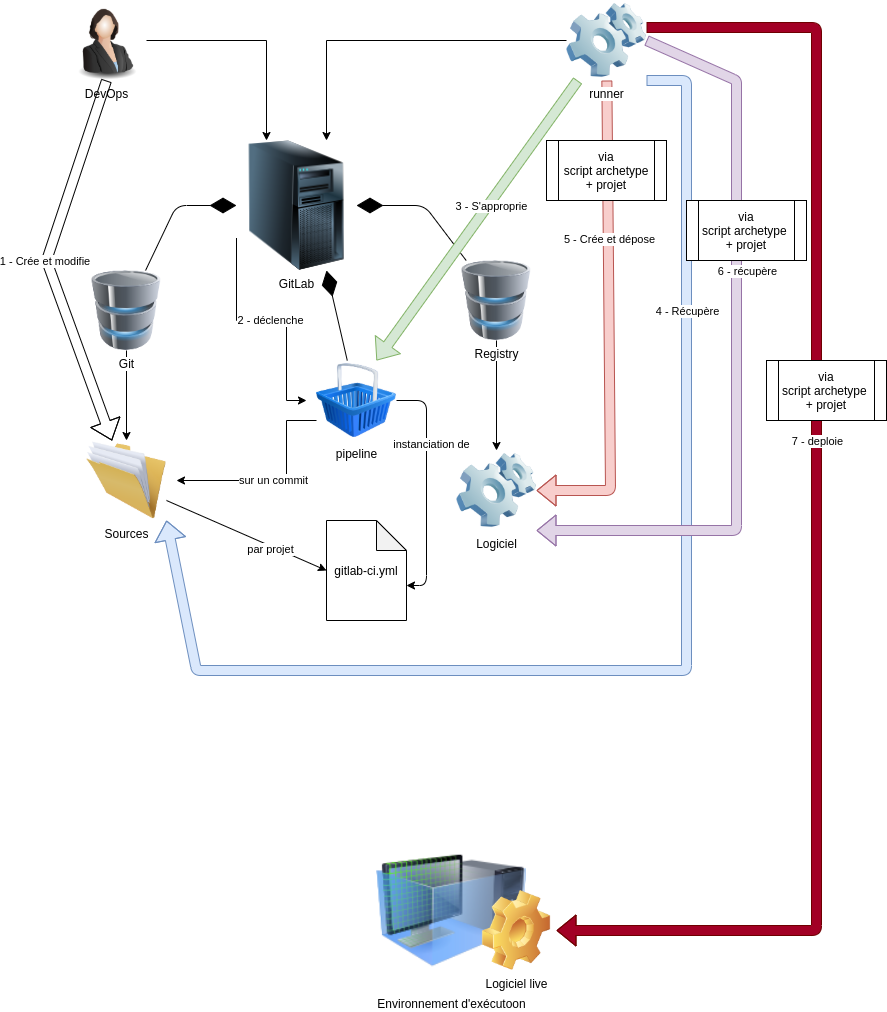
Par rapport aux diagrammes du début de l’article on voit que l’aspect conteneurisation a disparu de la réflexion. La solution sera bien sur conteneurisée mais l’implémentation ne doit pas être influencée par la conteneurisation.
Tags: CI/CD Docker Gitlab